主题模型(二)--pLSA&LDA
两个模型之一: pLSA模型
K个V 面的骰子
想象某个人要写 篇文档,他需要确定每篇文档里每个位置上的词。假定他一共有 个可选的主题,有 个可选的词项,所以,他制作了 个 面的 “主题-词项” 骰子,每个骰子对应一个主题,骰子每一面对应要选择的词项。然后,每写一篇文档会再制作一颗 面的 ”文档-主题“ 骰子;每写一个词,先扔该骰子选择主题;得到主题的结果后,使用和主题结果对应的那颗”主题-词项“骰子,扔该骰子选择要写的词。他不停的重复如上两个扔骰子步骤,最终完成了这篇文档。重复该方法 次,则写完所有的文档。在这个过程中,我们并未关注词和词之间的出现顺序,所以 也是一种词袋方法.
pLSA的图


概率图
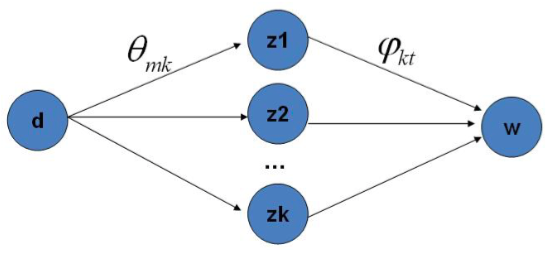
代表文档, 代表主题(隐含类别), 代表单词:

该模型假设一组共现(co-occurence)词项关联着一个隐含的主题类别 . 有如下三个相关的概率:
- 表示词在文档 中出现的概率;
- 表示某个主题 在给定文档 下出现的概率;
- 表示某词 在给定主题 下出现的概率;
pLSA的生成模型:
- 按照概率 选择一篇文档
- 按照概率 选择一个隐含的主题类别
- 按照概率 生成一个词
即:
其中, 根据贝叶斯网络性质,

从矩阵的角度理解 &
假设用 表示词表 在主题 上的一个多项分布,则 可以表示成一个向量,每个元素 表示词项 出现在主题 中的概率,即: 同样,假设用 表示所有主题 在文档 上的一个多项分布,则 可以表示成一个向量,每个元素 表示主题 出现在文档 中的概率,即: 最终我们要求解的参数是这两个矩阵:
目标函数
由于词和词之间是互相独立的,于是可以得到整篇文档 个词的分布: 并且文档和文档也是互相独立的,于是我们可以得到整个语料库的词的分布 (整个语料库 篇文档, 每篇文档 个词): 其中, 表示词项 在文档 中的词频,
样本分布的对数似然函数
其中, 表示文档 中词的总数, 总有
EM算法
我们需要最大化对数似然函数来求解参数,对于这种含有隐变量的最大似然估计,我们还是需要使用EM方法。
E-step: 假定参数已知,计算此时隐变量的后验概率。
M-step:带入隐变量的后验概率,最大化样本分布的对数似然函数,求解相应的参数。
观察上面的对数似然函数 ,由于 也就是文档长度可以单独从样本计算,可以去掉不影响最大化似然函数; 此外,根据E-step的计算结果,把 代入 ,于是我们最大化下面这个函数即可:
这是一个多元函数求极值问题,并且已知有如下约束条件:
一般处理这种带有约束条件的极值问题,我们常用的方法是拉格朗日乘数法,引入拉格朗日乘子把约束条件和多元函数结合在一起,转化为无条件极值问题。这里我们引入两个乘子 和 ,可以写出拉格朗日函数,如下:
需要求解 和 ,分别求偏导,取0,可得如下等式:
消去拉格朗日乘子,最终可估计出参数:
两个模型之二: LDA模型
LDA的图


概率图
在原始的pLSA模型中,我们求解出两个参数:“主题-词项”矩阵 和“文档-主题”矩阵 ,但是我们并未考虑参数的先验知识;而LDA的改进之处,是对这俩参数之上分别增加了先验分布,相应参数称作超参数(hyperparamter)。
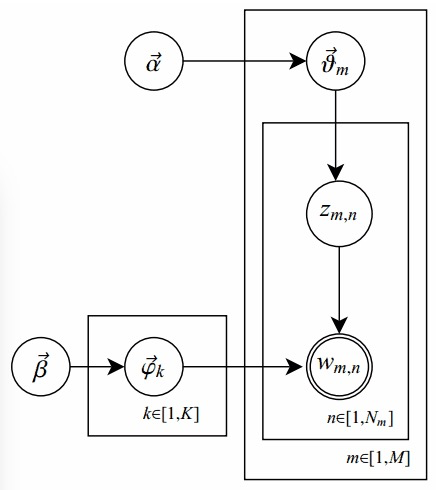
其中,单圆圈表示隐变量;双圆圈表示观察到的变量;把节点用方框(plate)圈起来,表示其中的节点有多种选择。所以这种表示方法也叫做plate notation.
对应到上图,只有 是观察到的变量,其他都是隐变量或者参数,其中 和 是超参数;方框中, 表示有 种“主题-词项”分布; 有 种“文档-主题”分布,即对每篇文档都会产生一个 分布;每篇文档 中有 个词,每个词 都有一个主题 ,该词实际是由 产生。
LDA的生成模型
在LDA中,“文档-主题”向量 由超参数为 的Dirichlet分布生成,“主题-词项”向量 由超参数为 的Dirichlet分布生成.
- 对所有的主题 (生成 : 矩阵):
- 生成“主题-词项”分布 ( 维向量,对应词表 中的每个词项的概率)
- 对所有的文档 (对应 : 矩阵)::
- 生成当前文档 相应的“文档-主题”分布 ( 维向量,即第 篇文档对应的每个主题的概率)
- 生成当前文档 的长度
- 对当前文档 中的所有词 :
- 生成当前位置的词的所属主题
- 根据之前生成的主题分布 ,生成当前位置的词的相应词项
目标函数
根据贝叶斯网络, 及所有已知信息和带超参数的隐变量,我们可以写出联合分布:
通过对 和 积分以及 求和,可以求得 的分布: 整个样本的分布:
求联合分布
求出联合分布 , 咱们便可以通过联合分布来计算在给定可观测变量 下的隐变量 的条件分布(后验分布) 来进行贝叶斯分析.
- 第一部分 表示的是根据确定的主题 和词分布的先验分布参数 采样词的过程, 独立于
- 第二部分 根据主题分布的先验分布参数 采样主题的过程, 独立于 。
求第一个因子
根据确定的主题 和从先验分布参数 采样得到的词分布 产生: 由于样本中的 ,这意味着,我们可以把上面的对词的乘积分解成对主题和对词项的两层乘积: 其中, 是词项 在主题 中出现的次数.
目标分布 需要对 积分:
求第二个因子
由于样本中的 ,这意味着,我们可以把上面的对词的乘积分解成对主题和对词项的两层乘积: 是单词 所属的文档, 是主题 在文章 中出现的次数
目标分布 , 需要对 积分:
最终得到联合分布
Gibbs 采样
所以,如果要完成Gibbs抽样,需要知道如下条件概率: 如果模型包含隐变量 ,通常需要知道后验概率分布 ,所以,包含隐变量的Gibbs抽样器公式如下:
LDA中的Gibbs采样
根据联合分布,求解下标为 的词,即第 篇文档中的第 个词, 的全部的条件概率。
令 . 其中, 和 的关系式如下:
LDA中的Gibbs采样:
这个公式的右边其实就是 , 这个概率其实是 的路径概率. 由于 有 个, 所以Gibbs Samppling 公式的物理意义就是在这 条路径中进行采样.
求参数 和
我们需要根据Markov链的状态 获取多项分布的参数 和 。根据贝叶斯法则和Dirichlet先验,以及公式(1)和(2): 求解Dirichlet分布的期望, 即可得:
LDA Gibbs采样流程

反馈与建议
- 微博:@Girl_AI
参考文献
- Thomas Hofmann, Unsupervised Learning by Probabilistic Latent Semantic Analysis, Machine Learning, 42, 177–196, 2001
- Gregor Heinrich, Parameter estimation for text analysis
- David M.Blei, Andrew Y.Ng, Michael I.Jordan, Latent Dirichlet Allocation
- Wang Yi. Distributed Gibbs Sampling of Latent Topic Models: The Gritty Details Technical report, 2005.
- LDA数学八卦-rickjin(翻墙可看)
- 主题模型之pLSA
- 主题模型之LDA
- 通俗理解LDA主题模型
- 七月算法机器学习在线班